Al describir grupos de observaciones, con frecuencia es conveniente resumir la información con un solo número. Este número que, para tal fin, suele situarse hacia el centro de la distribución de datos se denomina
medida o
parámetro de tendencia central o
de centralización. Cuando se hace referencia únicamente a la posición de estos parámetros dentro de la distribución, independientemente de que ésta esté más o menos centrada, se habla de estas medidas como
medidas de posición.
1 En este caso se incluyen también los
cuantiles entre estas medidas.
Entre las medidas de tendencia central tenemos:
Se debe tener en cuenta que existen variables cualitativas y variables cuantitativas, por lo que las medidas de posición o medidas de tendencia se usan de acuerdo al tipo de variable que se está observando, en este caso se observan variables cuantitativas.
La media aritmética
La media aritmética es el valor obtenido por la suma de todos sus valores dividida entre el número de sumandos.
Por ejemplo, las notas de 5 alumnos en una prueba:
niño nota
1 6,0 ·Primero, se suman las notas:
2 5,4 6,0+5,4+3,1+7,0+6,1 = 27,6
3 3,1 ·Luego el total se divide entre la cantidad de alumnos:
4 7,0 27,6/5=5,52
5 6,1
· La media aritmética en este ejemplo es 5,52
La
media aritmética es, probablemente, uno de los parámetros estadísticos más extendidos.
2 Se le llama también
promedio o, simplemente,
media.
Definición formal
Dado un conjunto numérico de datos, x1, x2, ..., xn, se define su media aritmética como

Esta definición varía, aunque no sustancialmente, cuando se trata de
variables continuas, esto es, también puede calcularse para variables agrupadas en
intervalos.
Propiedades
Las principales propiedades de la media aritmética son:
- Su cálculo es muy sencillo y en él intervienen todos los datos.
- Su valor es único para una serie de datos dada.
- Se usa con frecuencia para comparar poblaciones, aunque es más apropiado acompañarla de una medida de dispersión.
- Se interpreta como "punto de equilibrio" o "centro de masas" del conjunto de datos, ya que tiene la propiedad de equilibrar las desviaciones de los datos respecto de su propio valor:
-

- Minimiza las desviaciones cuadráticas de los datos respecto de cualquier valor prefijado, esto es, el valor de
 es mínimo cuando
es mínimo cuando  . Este resultado se conoce como Teorema de König. Esta propiedad permite interpretar uno de los parámetros de dispersión más importantes: la varianza.
. Este resultado se conoce como Teorema de König. Esta propiedad permite interpretar uno de los parámetros de dispersión más importantes: la varianza.
-
 entonces
entonces  , donde
, donde  es la media aritmética de los
es la media aritmética de los  , para i = 1, ..., n y a y b números reales.
, para i = 1, ..., n y a y b números reales.
Inconvenientes de su uso
Este parámetro, aún teniendo múltiples propiedades que aconsejan su uso en situaciones muy diversas, tiene también algunos inconvenientes, como son:
- Para datos agrupados en intervalos (variables continuas) su valor oscila en función de la cantidad y amplitud de los intervalos que se consideren.

La estatura media como resumen de una población homogénea (abajo) o heterogénea (arriba).
- Es una medida a cuyo significado afecta sobremanera la dispersión, de modo que cuanto menos homogéneos sean los datos, menos información proporciona. Dicho de otro modo, poblaciones muy distintas en su composición pueden tener la misma media.4 Por ejemplo, un equipo de baloncesto con cinco jugadores de igual estatura, 1,95 m, evidentemente, tendría una estatura media de 1,95 m, valor que representa fielmente a esta población homogénea. Sin embargo, un equipo de jugadores de estaturas más heterogéneas, 2,20 m, 2,15 m, 1,95 m, 1,75 m y 1,70 m, por ejemplo, tendría también, como puede comprobarse, una estatura media de 1,95 m, valor que no representa a casi ninguno de sus componentes.
- En el cálculo de la media no todos los valores contribuyen de la misma manera. Los valores altos tienen más peso que los valores cercanos a cero. Por ejemplo, en el cálculo del salario medio de un empresa, el salario de un alto directivo que gane 1.000.000 de € tiene tanto peso como el de diez empleados "normales" que ganen 1.000 €. En otras palabras, se ve muy afectada por valores extremos.
- No se puede determinar si en una distribución de frecuencias hay intervalos de clase abiertos.
Media aritmética ponderada
A veces puede ser útil otorgar pesos o valores a los datos dependiendo de su relevancia para determinado estudio. En esos casos se puede utilizar una media ponderada.
Si

son nuestros datos y

son sus "pesos" respectivos, la media ponderada se define de la siguiente forma:

Media muestral
Esencialmente, la media muestral es el mismo parámetro que el anterior, aunque el adjetivo "muestral" se aplica a aquellas situaciones en las que la media aritmética se calcula para un
subconjunto de la población objeto de estudio.
La media muestral es un parámetro de extrema importancia en la
inferencia estadística, siendo de gran utilidad para la
estimación de la media poblacional, entre otros usos.
Moda
La moda es el dato más repetido, el valor de la variable con mayor
frecuencia absoluta.
5 En cierto sentido la definición matemática corresponde con la locución "
estar de moda", esto es, ser lo que más se lleva.
Su cálculo es extremadamente sencillo, pues sólo necesita un recuento. En variables continuas, expresadas en intervalos, existe el denominado intervalo modal o, en su defecto, si es necesario obtener un valor concreto de la variable, se recurre a la
interpolación.
Por ejemplo, el número de personas en distintos vehículos en una carretera: 5-7-4-6-9-5-6-1-5-3-7. El número que más se repite es 5, entonces la moda es 5.
Hablaremos de una distribución bimodal de los datos, cuando encontremos dos modas, es decir, dos datos que tengan la misma frecuencia absoluta máxima. Cuando en una distribución de datos se encuentran tres o más modas, entonces es multimodal. Por último, si todas las variables tienen la misma frecuencia diremos que no hay moda.
Cuando tratamos con datos agrupados en intervalos, antes de calcular la moda, se ha de definir el intervalo modal. El intervalo modal es el de mayor frecuencia absoluta.
La moda, cuando los datos están agrupados, es un punto que divide el intervalo modal en dos partes de la forma p y c-p, siendo c la amplitud del intervalo, que verifiquen que:

Siendo

la frecuencia absoluta del intervalo modal y
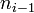
y

las frecuencias absolutas de los intervalos anterior y posterior, respectivamente, al intervalo modal.
Las calificaciones en la asignatura de Matemáticas de 39 alumnos de una clase viene dada por la siguiente tabla (debajo):
| Calificaciones | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|
| Número de alumnos | 2 | 2 | 4 | 5 | 8 | 9 | 3 | 4 | 2 |
|---|
Propiedades
Sus principales propiedades son:
- Cálculo sencillo.
- Interpretación muy clara.
- Al depender sólo de las frecuencias, puede calcularse para variables cualitativas. Es por ello el parámetro más utilizado cuando al resumir una población no es posible realizar otros cálculos, por ejemplo, cuando se enumeran en medios periodísticos las características más frecuentes de determinado sector social. Esto se conoce informalmente como "retrato robot".6
Inconvenientes
- Su valor es independiente de la mayor parte de los datos, lo que la hace muy sensible a variaciones muestrales. Por otra parte, en variables agrupadas en intervalos, su valor depende excesivamente del número de intervalos y de su amplitud.
- Usa muy pocas observaciones, de tal modo que grandes variaciones en los datos fuera de la moda, no afectan en modo alguno a su valor.
- No siempre se sitúa hacia el centro de la distribución.
- Puede haber más de una moda en el caso en que dos o más valores de la variable presenten la misma frecuencia (distribuciones bimodales o multimodales).
Mediana
La mediana es un valor de la variable que deja por debajo de sí a la mitad de los datos, una vez que éstos están ordenados de menor a mayor.
7 Por ejemplo, la mediana del número de hijos de un conjunto de trece familias, cuyos respectivos hijos son: 3, 4, 2, 3, 2, 1, 1, 2, 1, 1, 2, 1 y 1, es 2, puesto que, una vez ordenados los datos: 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 3, 3, 4, el que ocupa la posición central es 2:

En caso de un número par de datos, la mediana no correspondería a ningún valor de la variable, por lo que se conviene en tomar como mediana el valor intermedio entre los dos valores centrales. Por ejemplo, en el caso de doce datos como los siguientes:

Se toma como mediana

Existen métodos de cálculo más rápidos para datos más númerosos (véase el
artículo principal dedicado a este parámetro). Del mismo modo, para valores agrupados en intervalos, se halla el "intervalo mediano" y, dentro de éste, se obtiene un valor concreto por interpolación.
Cálculo de la mediana para datos agrupados
Primero hallamos las frecuencias absolutas acumuladas Fi (ver tabla del margen derecho).
Así, aplicando la formula asociada a la mediana para n impar, obtenemos X(39+1)/2 = X20 y basándonos en la fórmula que hace referencia a las frecuencias absolutas:
Ni-1< n/2 < i = N19 < 19.5 < N20
Por tanto la mediana será el valor de la variable que ocupe el vigésimo lugar. En nuestro ejemplo, 21 (frecuencia absoluta acumulada para Xi = 5) > 19.5 con lo que Me = 5 puntos (es aconsejable no olvidar las unidades; en este caso como estamos hablando de calificaciones, serán puntos)
La mitad de la clase ha obtenido un 5 o menos, y la otra mitad un 5 o más.
- Ejemplo (N par)
Las calificaciones en la asignatura de Matemáticas de 38 alumnos de una clase viene dada por la siguiente tabla (debajo):
| Calificaciones | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|
| Número de alumnos | 2 | 2 | 4 | 5 | 6 | 9 | 4 | 4 | 2 |
|---|
| xi | fi | Fi |
|---|
| 1 | 2 | 2 |
|---|
| 2 | 2 | 4 |
|---|
| 3 | 4 | 8 |
|---|
| 4 | 5 | 13 |
|---|
| 5 | 6 | 19 = 19 |
|---|
| 6 | 9 | 28 |
|---|
| 7 | 4 | 32 |
|---|
| 8 | 4 | 36 |
|---|
| 9 | 2 | 38 |
|---|
Calculemos la Mediana:
Primero hallamos las frecuencias absolutas acumuladas Fi (ver tabla margen derecho).
Si volvemos a utilizar la fórmula asociada a la mediana para n par, obtenemos X(38/2) = X19 y basándonos en la fórmula que hace referencia a las frecuencias absolutas --> Ni-1< n/2 < Ni = N18 < 19 < N19
Con lo cual la mediana será la media aritmética de los valores de la variable que ocupen el decimonoveno y el vigésimo lugar.
En nuestro ejemplo, el lugar decimonoveno lo ocupa el 5 y el vigésimo el 6, (desde el vigésimo hasta el vigésimo octavo)
con lo que Me = (5+6)/2 = 5,5 puntos.
Propiedades e inconvenientes
Las principales propiedades de la mediana son:
- Es menos sensible que la media a oscilaciones de los valores de la variable. Un error de transcripción en la serie del ejemplo anterior en, pongamos por caso, el último número, deja a la mediana inalterada.
- Como se ha comentado, puede calcularse para datos agrupados en intervalos, incluso cuando alguno de ellos no está acotado.
- No se ve afectada por la dispersión. De hecho, es más representativa que la media aritmética cuando la población es bastante heterogénea. Suele darse esta circunstancia cuando se resume la información sobre los salarios de un país o una empresa. Hay unos pocos salarios muy altos que elevan la media aritmética haciendo que pierda representatividad respecto al grueso de la población. Sin embargo, alguien con el salario "mediano" sabría que hay tanta gente que gana más dinero que él, como que gana menos.
Sus principales inconvenientes son que en el caso de datos agrupados en intervalos, su valor varía en función de la amplitud de estos. Por otra parte, no se presta a cálculos algebraicos tan bien como la media aritmética.











![S_Y^2 = \frac{\sum (Y_i - \bar{Y})^2}{n} = \frac{\sum [(X_i + k) - (\bar{X} + k)]^2}{n} = \frac{\sum (X_i + k - \bar{X} - k)^2}{n} = \frac{\sum (X_i - \bar{X})^2}{n} = S_X^2](https://lh3.googleusercontent.com/blogger_img_proxy/AEn0k_vJ5ukP8i_Pu9RF0fpYnaOzw_9NQMvEyDRy5Bn3AlPBs_3qt0bEfHfHs-HA4OOG6JtNjgFV-BdaqwkWDijmW8HEVSnAA_UteS0JEfLGd0DQWqj8mBpf9fuqT9X8ef9xedbcZP_YMHBgXJ3X1u3mNA=s0-d)

![S_Y^2 = \frac{\sum (Y_i - \bar{Y})^2}{n} = \frac{\sum (X_i \cdot k - \bar{X} \cdot k)^2}{n} = \frac{\sum [k \cdot (X_i - \bar{X})]^2}{n} = \frac{\sum [k^2 \cdot (X_i - \bar{X})^2]}{n} = k^2 \cdot \frac{\sum (X_i - \bar{X})^2}{n} = k^2 \cdot S_X^2](https://lh3.googleusercontent.com/blogger_img_proxy/AEn0k_vws1IEBmqXKNMFGZiHRs6WDCIIl-Q6vj02mpbvzVUmCS4o_8EOSDzbainSUANBsJLa54RLB8Qfmsu4Vdz1qDquAHI0hyxEeeEB7xMs0_dCgj1AkMUSms00q4ONdVBr-vvL8_V2j7yeftEXettZ=s0-d)
 cov
cov 


 ".
".




![r = \frac{n\sum x_i y_i - \sum x_i \sum y_i}
{\sqrt{\left[n\sum x_i^2 - \left(\sum x_i\right)^2\right]
\left[n\sum y_i^2 - \left(\sum y_i\right)^2\right]}}](https://lh3.googleusercontent.com/blogger_img_proxy/AEn0k_u9eUqFdPtdyZNC-xVRxkbj6m7FGZv0o4D2GP2oUNYZJ1i70F-VVV7nzwQnjBLawpngIHxehfdly4Cs8bpxZLFN73SEWPtbWJFBaOS9pqsRyTVy8viDUjrNJNAwIq41iK6wpcz4htANXV0yBD07Qw=s0-d)
